[번역] React 리스트 비교(diff)에서 'key'는 어떻게 동작하나요?
React Internals Deep Dive - EP19
![[번역] React 리스트 비교(diff)에서 'key'는 어떻게 동작하나요?](/_next/image?url=https%3A%2F%2Fcdn.hashnode.com%2Fres%2Fhashnode%2Fimage%2Fupload%2Fv1715918700012%2F895e6886-63db-46ed-807b-18c1216cd815.jpeg&w=3840&q=75)
영문 블로그 글을 번역했습니다. 허가를 받으면 시리즈를 이어갈 예정입니다.
원문링크: https://jser.dev/react/2022/02/08/the-diffing-algorithm-for-array-in-react
ℹ️React Internals Deep Dive 에피소드 19, 유튜브에서 제가 설명하는 것을 시청해주세요.
⚠React@18.2.0기준, 최신 버전에서는 구현이 변경되었을 수 있습니다.
💬 역자 주석: JSer의 코멘트는 ❗❗로 표시 해뒀습니다.
그 외 주석은 리액트 소스 코드 자체의 주석입니다.
... 은 생략된 코드입니다.
각 항목에 key를 추가하지 않고 리스트를 렌더링하면 경고가 표시됩니다.

그 이유는 홈페이지에 꽤 잘 설명되어 있지만 설명은 개념적인 것이므로 key가 내부적으로 정확히 어떻게 작동하는지 살펴보고 손을 더럽혀(💬직접 분해해서 분석해본다는 의미) 보겠습니다.
reconcileChildrenArray()
우리는 이미 코드 베이스에 약간 익숙해졌으므로 배열에 대한 조정(reconciliation) 함수인 reconcileChildrenArray()를 대상으로 삼는 것은 어렵지 않을 것입니다. (소스)
그렇지 않다면, 제 블로그에서 지난 글을 검색하거나 제 유튜브 동영상 시리즈를 시청하세요.
함수 본문은 긴 주석 단락으로 시작하여 약간 위협적입니다.
// This algorithm can't optimize by searching from both ends since we
// don't have backpointers on fibers. I'm trying to see how far we can get
// with that model. If it ends up not being worth the tradeoffs, we can
// add it later.
// Even with a two ended optimization, we'd want to optimize for the case
// where there are few changes and brute force the comparison instead of
// going for the Map. It'd like to explore hitting that path first in
// forward-only mode and only go for the Map once we notice that we need
// lots of look ahead. This doesn't handle reversal as well as two ended
// search but that's unusual. Besides, for the two ended optimization to
// work on Iterables, we'd need to copy the whole set.
// In this first iteration, we'll just live with hitting the bad case
// (adding everything to a Map) in for every insert/move.
💬 주석 번역
// 이 알고리즘은 파이버에 백포인터가 없기 때문에 양쪽 끝에서 검색하여 최적화할 수 없습니다.
// 이 모델로 얼마나 멀리 갈 수 있는지 알아보고 있습니다.
// 그만한 가치가 없다고 판단되면 나중에 추가할 수 있습니다.
// 양단 최적화를 사용하더라도 변경 사항이 거의 없는 경우에 최적화하고
// 맵 대신 무차별 대입(brute force)을 통해 비교하는 것이 좋습니다.
// forword-only 모드에서 먼저 해당 경로를 탐색한 후,
// 전방 시야가 많이 필요하다는 것을 알게 된 후에야 맵으로 이동하는 것이 좋습니다.
// 반전 검색과 양쪽 끝 검색은 처리하지 못하지만 이는 드문 경우입니다.
// 검색을 사용하지만 이는 드문 경우입니다. 게다가 이터러블에서 두 가지 끝 최적화가 작동하려면
// 전체 세트를 복사해야 합니다.
// 이 첫 번째 반복(iteration)에서는 삽입/이동할 때마다 나쁜 경우
// (맵에 모든 것을 추가하는 경우)를 처리하는 것으로 만족하겠습니다.
파이버에 백포인터가 없기 때문에 React가 여기서 양단(two ended) 최적화를 수행하지 않고 타협하는 것처럼 보입니다.
앞의 항목에서 우리는 자식의 경우 React가 배열이 아닌 '형제'별로 파이버의 링크드 리스트를 보유한다는 것을 알 수 있습니다.
양단 최적화란 무엇인가요? 시작이 아닌 끝에서 스캔하는 알고리즘일 것 같습니다. 이것이 첫 번째 문제로 이어집니다.
리스트에 어떤 종류의 변경이 발생할 수 있나요?
배열이 있다고 가정해 보겠습니다.
const arrPrev = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
몇 가지 작업이 끝나면, 새로운 배열이 됩니다. 인덱스 i에서 어떤 엘리먼트가 다른 것을 발견하면 수정할 수 있는 가능성이 많을 수 있습니다.
인덱스
i에 새 엘리먼트가 삽입됩니다.새 요소가 인덱스
i에서 이전 엘리먼트를 대체하고 있습니다.기존 엘리먼트가 다른 인덱스에서
i로 이동합니다.기존 엘리먼트가 다른 인덱스에서 이동되어 인덱스
i의 이전 엘리먼트를 대체합니다.이전 엘리먼트
i가 제거되면 다음 엘리먼트가 그 위치를 차지합니다....
추가 분석 없이는 어떤 경우인지 파악하기 어렵다는 것을 알 수 있습니다.
새 배열이 있다고 가정해 보겠습니다.
const arrNext = [11, 12, 9, 4, 7, 16, 1, 2, 3];
최소한의 비용으로 어떻게 변환해야 할까요?
최소 이동에 관심이 있다면 레벤슈타인 거리와 비슷하지만 최소 이동을 찾은 후에도 변환을 수행해야 합니다.
총 비용 = 분석(조정) 비용 + 변환(변경 커밋) 비용
극단적인 예를 들어 배열을 뒤집어 보면 어떨까요?
const arrPrev = [10, 9, 8, 7, 6, 5, 4, 3, 2, 1];
각 위치가 다르기 때문에 최적의 움직임을 찾는 데 분석하는 데 많은 시간이 소요되므로 모든 위치를 교체하는 것이 더 나을 수 있습니다.
물론 더미 접근 방식을 취할 수 있습니다. 모든 다른 위치를 새 항목으로 교체하는 것으로 취급합니다.
다음과 같은 경우를 생각하면 왜 두 가지 끝이 있는 최적화가 있는지 이해하는 데 도움이 됩니다.
const arrPrev = [1, 2, 3, 4, 5,6, 7, 8, 9, 10];
const arrNext = [11, 12, 7, 8, 9, 10];
머리로 추론하기는 어렵지만 반대로 생각하면 다음과 같습니다.
const arrPrev = [10, 9, 8, 7, 6, 5, 4, 3, 2, 1];
const arrNext = [10, 9, 8, 7, 6, 12, 11];
이제 훨씬 명확해 보입니다. 이게 양방향 최적화가 맞나요? 제가 틀렸을 수도 있습니다.
React의 접근 방식
아래 코드를 더 잘 이해하기 위해 조금 설명해 드리겠습니다.
기본적으로 React는 다음 단계에 따라 새 파이버 리스트를 구성합니다.
동일한 키로 항목을 낙관적으로 비교하기
둘 다 인덱스 0에서 시작합니다, (headOld, headNew)
이전 파이버와 새 엘리먼트를 비교합니다.
운이 좋아 키가 같으면, 조정할 수 있다는 메모를 남깁니다.
그렇지 않은 경우, 중단
나머지는
key별로 오래된 파이버를 재사용할 수 있는지 확인합니다.가능하다면 향후 조정에 사용하세요.
그렇지 않은 경우 새롭게 만듭니다
사용하지 않는 파이버 삭제
즉, React가 핵심 불일치를 발견하면 "이동"하거나 "새로운 파이버를 생성"하려고 시도합니다.
React 소스 코드로 돌아가 보겠습니다. 오래된 파이버와 새로운 엘리먼트를 비교하는 for 루프로 시작합니다.
for (; oldFiber !== null && newIdx < newChildren.length; newIdx++) {
if (oldFiber.index > newIdx) {
nextOldFiber = oldFiber;
oldFiber = null;
} else {
nextOldFiber = oldFiber.sibling;
}
const newFiber = updateSlot(
returnFiber,
oldFiber,
newChildren[newIdx],
lanes
);
if (newFiber === null) {
// a better way to communicate whether this was a miss or null,
// boolean, undefined, etc.
if (oldFiber === null) {
oldFiber = nextOldFiber;
}
break;
}
if (shouldTrackSideEffects) {
if (oldFiber && newFiber.alternate === null) {
// We matched the slot, but we didn't reuse the existing fiber, so we
// need to delete the existing child.
deleteChild(returnFiber, oldFiber);
}
}
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);
if (previousNewFiber === null) {
// TODO: Move out of the loop. This only happens for the first run.
resultingFirstChild = newFiber;
} else {
// TODO: Defer siblings if we're not at the right index for this slot.
// I.e. if we had null values before, then we want to defer this
// for each null value. However, we also don't want to call updateSlot
// with the previous one.
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
oldFiber = nextOldFiber;
}
이런, 도대체 무슨 일이 벌어지고 있는 거죠? 차근차근 설명해 보겠습니다. 댓글을 추가했습니다.
for (; oldFiber !== null && newIdx < newChildren.length; newIdx++) {
// ❗❗ 이 루프는 새로운 엘리먼트들을 통과합니다.
// ❗❗ oldFiber를 계속 추적하는데, 투-포인터 알고리즘과 유사해 보입니다.
// ❗❗ 두 개의 정렬된 배열을 병합하라는 문제를 떠올려 보세요.
if (oldFiber.index > newIdx) {
nextOldFiber = oldFiber;
oldFiber = null;
} else {
nextOldFiber = oldFiber.sibling;
}
// ❗❗ 자식 파이버들은 형제로 연결되어 있기 때문에
// ❗❗ 인덱스는 배열에서의 위치를 표시하는 것입니다.
// ❗❗ 여기서 말하길:
// ❗❗ 이상적으로는 두 포인터가 모두 앞으로 나아가고 아무것도 올바르게 변경되지 않습니다.
// ❗❗ 하지만 빈 값들이 존재한다는것을 생각해 보면,
// ❗❗ 인덱스가 위치가 반드시 정확하지는 않을 수 있습니다.
// ❗❗ (빈 값에 대한 이전 포스팅 참조)
// ❗❗ 그래서 만약 olderFiber의 인덱스가 더 크다는 건, 새 자식이 null과 비교되고 있다는 의미입니다.
// ❗❗ 이 새 자식 또한 null일 수도 있다는것도 유의하세요.
const newFiber = updateSlot(
returnFiber,
oldFiber,
newChildren[newIdx],
lanes
);
// ❗❗ 이제 우리는 이전과 새로운 것을 비교하여 일치 할 수 있기를 바랍니다.
// ❗❗ updateSlot() 함수를 열면, 우리는 다음과 같은 것을 볼 수 있는데
// ❗❗ 만약 새 자식이 빈 값이거나 키가 일치하지 않으면
// ❗❗ 그러면 newFiber는 null입니다.
if (newFiber === null) {
// ❗❗ 만약 newFiber가 null이면,
// ❗❗ 우리는 확실하게 원래 위치를 찾거나 새 파이버를 만들 수 있는거죠?
// ❗❗ 그래서 여기서 멈춥(break)니다.
// this is to revert the variable
if (oldFiber === null) {
oldFiber = nextOldFiber;
}
break;
}
if (shouldTrackSideEffects) {
if (oldFiber && newFiber.alternate === null) {
// ❗❗ 이제 우리는 newFiver가 있는데, 만약 oldFiber와 동일한 타입이면
// ❗❗ 그러면 이것들은 alternate로 연결되야 합니다.
// ❗❗ 만약 아니라면, 교체해야됩니다, 그래서 oldFiber를 삭제해야 합니다.
// We matched the slot, but we didn't reuse the existing fiber, so we
// need to delete the existing child.
deleteChild(returnFiber, oldFiber);
}
}
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);
// ❗❗ 새로운 파이버를 성공적으로 확보했습니다.
// ❗❗ 우리는 파이버에 표시해서 리액트에게 알려줘야 합니다.
// ❗❗ DOM 노드를 새 인덱스에 넣는 것을 말이죠.
// ❗❗ lastPlacedIndex 는 아주 흥미로운데, 이 글에서 이후에 자세히 다루겠습니다.
// ❗❗ 파이버들을 체이닝해야 하네요 맞죠?
// ❗❗ previousNewFiber 를 사용하면 그렇게 할 수 있습니다.
if (previousNewFiber === null) {
resultingFirstChild = newFiber;
} else {
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
oldFiber = nextOldFiber;
}
이제 좀 더 명확해졌죠? 이 코드를 이해하기 위한 핵심은 다음과 같습니다.
oldFiber.index > newIdx를 비교하는 이유newFiber가 null 이 되는 시점
어쨌든 다음 부분은 간단해 보입니다.
if (newIdx === newChildren.length) {
// We've reached the end of the new children. We can delete the rest.
deleteRemainingChildren(returnFiber, oldFiber);
if (getIsHydrating()) {
const numberOfForks = newIdx;
pushTreeFork(returnFiber, numberOfForks);
}
return resultingFirstChild;
// ❗❗ 네, 이름에 따라 첫 번째 자식을 반환합니다.
// ❗❗ reconcileChildren은 부모에 대해 실행되기 때문에
// ❗❗ 첫 번째 자식은 workInProgress.child = reconcileChildFibers()를 설정하는데 필요합니다.
// ❗❗ reconcileChildren() 는 준비 과정일 뿐이며,
// ❗❗ 각 자식은 여전히 조정되어야 한다는 점에 유의하세요.
}
💬 reconcileChildFibers() 코드 링크
계속
if (oldFiber === null) {
// If we don't have any more existing children we can choose a fast path
// since the rest will all be insertions.
for (; newIdx < newChildren.length; newIdx++) {
const newFiber = createChild(returnFiber, newChildren[newIdx], lanes);
if (newFiber === null) {
continue;
}
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);
if (previousNewFiber === null) {
resultingFirstChild = newFiber;
} else {
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
}
return resultingFirstChild;
}
퍼즐의 마지막 조각
const existingChildren = mapRemainingChildren(returnFiber, oldFiber);
// ❗❗ 아직 확인해야할 새 자식이 있으므로
// ❗❗ 존재하는 파이버에서 같은 key를 찾을 수 있는지 알아 봅시다.
// ❗❗ 만약 발견되면 미래 조정에서 그것들을 사용할 수 있습니다.
// ❗❗ 빠른 탐색을 위해 모든 자식을 key map에 추가합니다.
// ❗❗ 여기서 다시 배열로 변경하면 됩니다.
// ❗❗ 계속 스캔하면서 map을 사용하여 삭제된 항목을 이동(move)로 복원할 수 있습니다.
for (; newIdx < newChildren.length; newIdx++) {
// `updateFromMap` is like `updateSlot`
// but try to get fiber from the fiber map
const newFiber = updateFromMap(
existingChildren,
returnFiber,
newIdx,
newChildren[newIdx],
lanes
);
if (newFiber !== null) {
// handle deletion again.
if (shouldTrackSideEffects) {
if (newFiber.alternate !== null) {
existingChildren.delete(newFiber.key === null ? newIdx : newFiber.key);
}
}
lastPlacedIndex = placeChild(newFiber, lastPlacedIndex, newIdx);
if (previousNewFiber === null) {
resultingFirstChild = newFiber;
} else {
previousNewFiber.sibling = newFiber;
}
previousNewFiber = newFiber;
}
}
if (shouldTrackSideEffects) {
// Any existing children that weren't consumed above were deleted. We need
// to add them to the deletion list.
existingChildren.forEach((child) => deleteChild(returnFiber, child));
}
return resultingFirstChild;
휴, 코드가 많긴 하지만 그래도 잘 다룰 수 있었습니다. 이제 좀 더 익숙해지셨나요?
잠깐만요, placeChild()에 대해 이야기해야 합니다.
function placeChild(
newFiber: Fiber,
lastPlacedIndex: number,
newIndex: number
): number {
newFiber.index = newIndex;
const current = newFiber.alternate;
if (current !== null) {
// ❗❗ current가 null이 아니면, 이동(move)일 수 있다는 의미입니다.
const oldIndex = current.index;
if (oldIndex < lastPlacedIndex) {
// ❗❗ oldIndex가 더 작으면, 이동이라는 의미입니다.
newFiber.flags |= Placement;
return lastPlacedIndex;
// ❗❗ 오래된 lastPlacedIndex를 반환한다는건, 증가하지 않는다는 의미입니다.
} else {
// This item can stay in place.
// return the index, which should increment.
return oldIndex;
}
} else {
// This is an insertion.
newFiber.flags |= Placement;
return lastPlacedIndex;
}
}
여기 코드를 이해하기가 조금 어렵습니다. 다음 사항에 유의하세요.
insertion을 위해 파이버가 새로 생성되고,Placement는 DOM 노드가 수집됨을 의미합니다.move하는 경우, 또한 뒤로 또는 앞으로 이동해야 합니다.backward로 이동하면 파이버가 사라지기 전에 올바른 위치에 남겨두기 때문에 아무것도 할 필요가 없습니다.forward라면, 우리는 실제 이동을 해야 합니다.appendChild()가 기본적으로 이동을 수행하기 때문에Placement가 이동합니다.
이를 위해 다음과 같이 주문 변경이 있다고 가정하고 그림을 그려 보겠습니다.
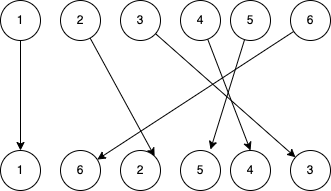
2, 5, 4, 3이 이동하면 6이 자동으로 1의 형제 항목으로 배치되기 때문에 6은 실제로 이동되지 않은 상태로 유지될 수 있습니다.
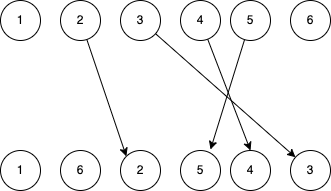
2 앞에 6을 삽입하는 것처럼 반대로 하면 어떨까 싶을 수도 있습니다. 링크드 리스트를 만드는 중이므로 파이버를 처리하는 동안에는 파이버의 형제를 알 수 없다는 점을 기억하세요. 그렇기 때문에 위의 6의 경우 2를 처리할 때 2를 그 형제로만 설정했습니다.
위의 경우 lastPlacedIndex는
먼저 0으로 설정하지만, 찾는 위치는 변경되지 않으므로, 이동할 필요가 없습니다.
6을 비교하면, 뒤로 이동하는 경우 이동할 필요가 없습니다. 5로 돌아옵니다.
2와 비교하면 이전 인덱스는 1 , 5보다 작으며, 앞으로 이동합니다.
5와 비교하면 이전 인덱스는 4 , 5보다 작으며, 앞으로 이동합니다.
4와 비교하면 이전 인덱스는 3 , 5보다 작으며, 앞으로 이동합니다.
3과 비교하면 이전 인덱스는 2 , 5보다 작으며, 앞으로 이동합니다.
참고로, Placement 뒤에 있는 코드는 커밋 단계에 있습니다.(출처)
이건 꽤나 간단합니다.
function insertOrAppendPlacementNode(
node: Fiber,
before: ?Instance,
parent: Instance
): void {
const { tag } = node;
const isHost = tag === HostComponent || tag === HostText;
if (isHost) {
const stateNode = node.stateNode;
if (before) {
insertBefore(parent, stateNode, before);
} else {
appendChild(parent, stateNode);
}
} else if (tag === HostPortal) {
// If the insertion itself is a portal, then we don't want to traverse
// down its children. Instead, we'll get insertions from each child in
// the portal directly.
} else {
const child = node.child;
if (child !== null) {
insertOrAppendPlacementNode(child, before, parent);
let sibling = child.sibling;
while (sibling !== null) {
insertOrAppendPlacementNode(sibling, before, parent);
sibling = sibling.sibling;
}
}
}
}
그게 다입니다. 다른 알고리즘은 실제로 그리 복잡하지 않으므로 이 게시물이 이해에 도움이 되었기를 바랍니다.
(원본 게시일: 2022-02-08)


